s = requests.session() s.keep_alive =False#防止源代码过长,超时导致SSL错误
htmls=etree.HTML(html)
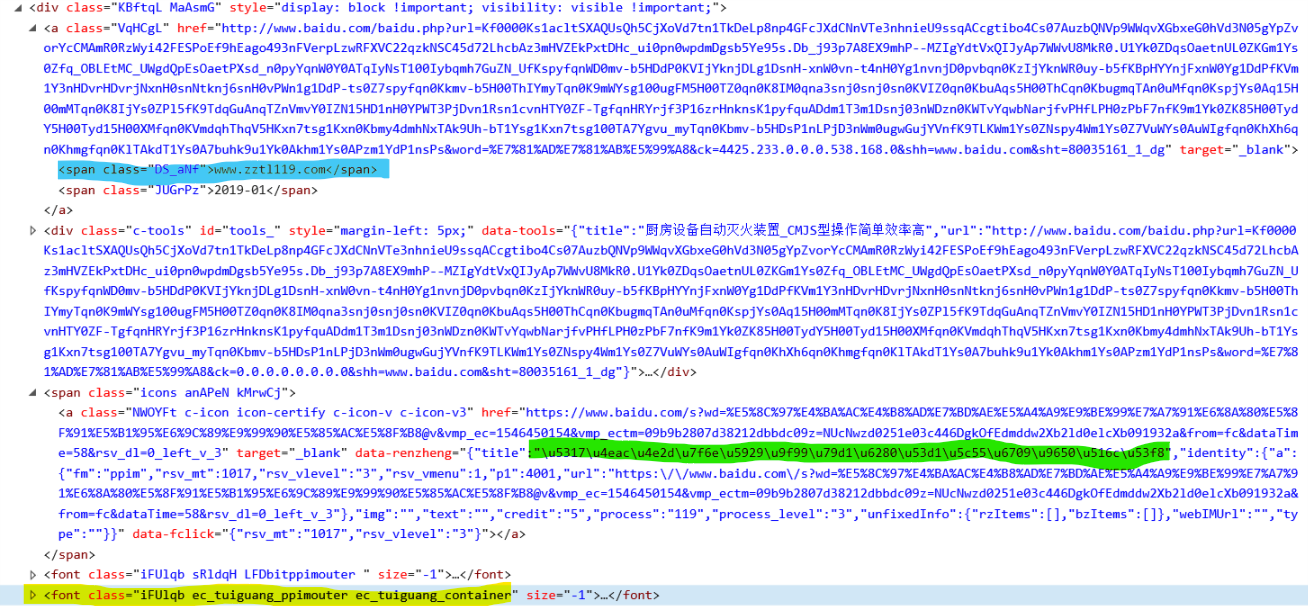
fonts=htmls.xpath("//*[contains(@class,'ec_tuiguang_container')]/parent::*/span/a/@data-renzheng")#定位 website=htmls.xpath("//*[contains(@class,'ec_tuiguang_container')]/parent::*/a/span[1]/text()") self.title=[] #公司名字 self.web=[] #公司网址 for i in website: self.web.append(i) for i in fonts: self.title.append(loads(i)['title']) except: self.title=[] self.web=[]