本文最后更新于 2024年6月7日 下午
基本用法
panic 能够改变程序的控制流,调用 panic 后会立刻停止执行当前函数的剩余代码,并在当前 Goroutine 中递归执行调用方的 defer。panic 只会触发当前 Goroutine 的 defer,panic 允许在 defer 中嵌套多次调用;recover 可以中止 panic 造成的程序崩溃。它是一个只能在 defer 中发挥作用的函数,在其他作用域中调用不会发挥作用;
数据结构
1
2
3
4
5
6
7
8
9
10
| type _panic struct {
argp unsafe.Pointer
arg interface{}
link *_panic
recovered bool
aborted bool
pc uintptr
sp unsafe.Pointer
goexit bool
}
|
argp 是指向 defer 调用时参数的指针;arg 是调用 panic 时传入的参数;link 指向了更早调用的 runtime._panic 结构;recovered 表示当前 runtime._panic 是否被 recover 恢复;aborted 表示当前的 panic 是否被强行终止;pc 程序计数器;sp 堆栈指针;goexit 是为了配合 pc 和 sp 修复 runtime.Goexit 带来的问题引入的;
原理
defer
defer 是一个面向编译器的声明,他会让编译器做两件事:
- 编译器会将 defer 声明编译为
runtime.deferproc(fn),这样运行时,会调用 runtime.deferproc,在 deferproc 中将 defer 挂到 Goroutine 的 defer 链上;
- 编译器会在函数
return 之前(注意,是 return 之前,而不是 return xxx 之前,后者不是一条原子指令),增加 runtime.deferreturn 调用;这样运行时,开始处理前面挂在 defer 链上的所有 defer。
deferreturn 会先判断链表有没有 defer,然后 jmpdefer 去做 defer 声明的事情。
panic
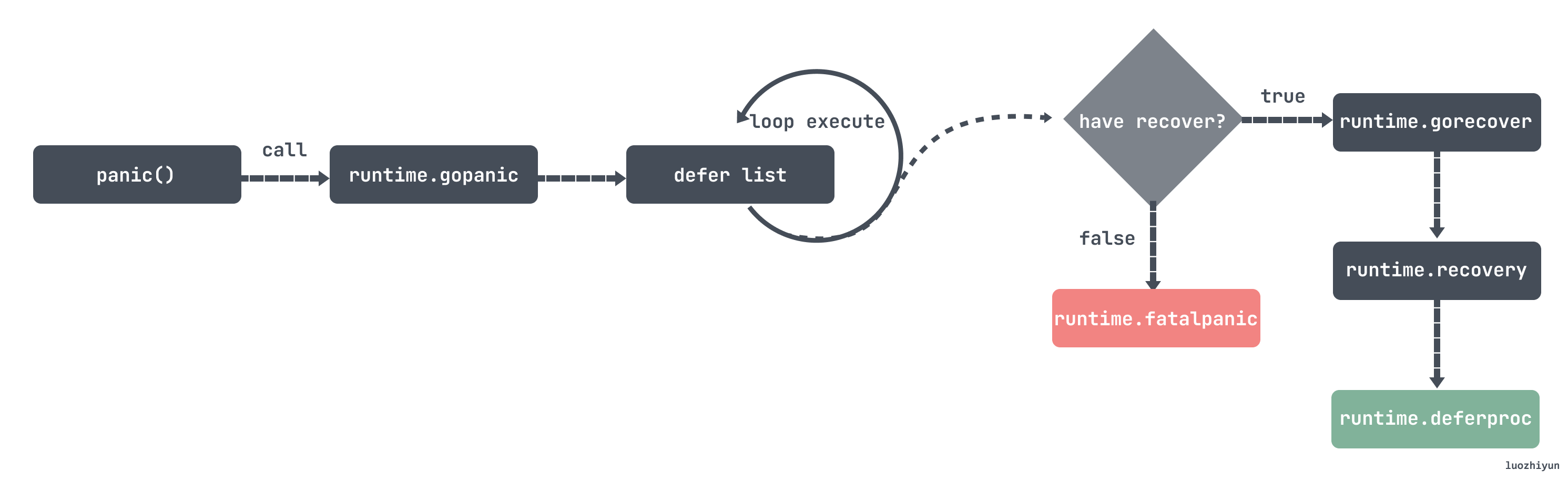
编译器会将关键字 panic 转换成 runtime.gopanic 该函数的执行过程包含以下几个步骤:
- 创建新的
runtime._panic 并添加到所在 Goroutine 的 _panic 链表的最前面;
- 在循环中不断从当前 Goroutine 的
_defer 中链表获取 runtime._defer 并调用 runtime.reflectcall 运行 defer 函数;
- 如果循环退出,则调用
runtime.fatalpanic 中止整个程序;
runtime.fatalpanic 实现了无法被恢复的程序崩溃,它在中止程序之前会通过 runtime.printpanics 打印出全部的 panic 消息以及调用时传入的参数;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| func gopanic(e interface{}) {
gp := getg()
...
var p _panic
p.arg = e
p.link = gp._panic
gp._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
for {
d := gp._defer
if d == nil {
break
}
d._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
d._panic = nil
d.fn = nil
gp._defer = d.link
...
pc := d.pc
sp := unsafe.Pointer(d.sp)
freedefer(d)
if p.recovered {
gp._panic = p.link
for gp._panic != nil && gp._panic.aborted {
gp._panic = gp._panic.link
}
if gp._panic == nil {
gp.sig = 0
}
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
mcall(recovery)
throw("recovery failed")
}
}
fatalpanic(gp._panic)
*(*int)(nil) = 0
}
|
recover
到这里我们已经掌握了 panic 退出程序的过程,接下来将分析 defer 中的 recover 是如何中止程序崩溃的。编译器会将关键字 recover 转换成 runtime.gorecover:
1
2
3
4
5
6
7
8
9
| func gorecover(argp uintptr) interface{} {
gp := getg()
p := gp._panic
if p != nil && !p.recovered && argp == uintptr(p.argp) {
p.recovered = true
return p.arg
}
return nil
}
|
该函数的实现很简单,如果当前 Goroutine 没有调用 panic,或 panic 已经被 recover 恢复过了那么该函数会直接返回 nil,这也是崩溃恢复在非 defer 中调用会失效的原因。
在正常情况下,它会修改 runtime._panic 的 recovered 字段,runtime.gorecover 函数中并不包含恢复程序的逻辑,程序的恢复是由 runtime.gopanic 函数负责的。
二者配合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| func gopanic(e interface{}) {
...
for {
...
pc := d.pc
sp := unsafe.Pointer(d.sp)
...
if p.recovered {
gp._panic = p.link
for gp._panic != nil && gp._panic.aborted {
gp._panic = gp._panic.link
}
if gp._panic == nil {
gp.sig = 0
}
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
mcall(recovery)
throw("recovery failed")
}
}
...
}
|
当 gorecover 设置了 p.recovered,gopanic 便会执行 p.recovered=true 对应的分支,它从 runtime._defer 中取出了 defer 的程序计数器 pc 和栈指针 sp 并调用 runtime.recovery 函数触发 Goroutine 的调度,调度之前会准备好 sp、pc 以及函数的返回值:
recovery
1
2
3
4
5
6
7
8
9
10
| func recovery(gp *g) {
sp := gp.sigcode0
pc := gp.sigcode1
gp.sched.sp = sp
gp.sched.pc = pc
gp.sched.lr = 0
gp.sched.ret = 1
gogo(&gp.sched)
}
|
runtime.recovery 将调用 defer 的 pc 和 sp 设置到了当前 goroutine 的 sched 上,并且将 ret 设置为 1,然后执行 gogo 调度。
从 runtime.deferproc 的注释中我们会发现,当 runtime.deferproc 函数的返回值是 1 时,编译器生成的代码会直接跳转到调用方函数返回之前执行,
根据我们之前的在 defer 章节的论述(编译器会在函数 return 之前,增加 runtime.deferreturn 调用。
因此,程序会跳转到 runtime.deferreturn 调用,runtime.deferreturn 会开始处理下一个 defer,直到 defer 的链表为空,继续执行程序的正常流程,也即是退出。
小结
无法捕获的 panic
内存溢出
1
2
3
4
5
6
7
8
9
10
11
| func main() {
defer errorHandler()
_ = make([]int64, 1<<40)
fmt.Println("can recover")
}
func errorHandler() {
if r := recover(); r != nil {
fmt.Println(r)
}
}
|
map 并发读写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func main() {
defer errorHandler()
m := map[string]int{}
go func() {
for {
m["x"] = 1
}
}()
for {
_ = m["x"]
}
}
func errorHandler() {
if r := recover(); r != nil {
fmt.Println(r)
}
}
|
栈内存耗尽
1
2
3
4
5
6
7
8
| func main() {
defer errorHandler()
var f func(a [1000]int64)
f = func(a [1000]int64) {
f(a)
}
f([1000]int64{})
}
|
对于栈不熟悉的同学可以看这篇文章: 一文教你搞懂 Go 中栈操作 。下面我简单说一下,栈的基本机制。
在Go中,Goroutines 没有固定的堆栈大小。相反,它们开始时很小(比如4KB),在需要时增长/缩小,似乎给人一种 "无限 "堆栈的感觉。但是增长总是有限的,但是这个限制并不是来自于调用深度的限制,而是来自于堆栈内存的限制,在Linux 64位机器上,它是1GB。
尝试将 nil 函数交给 goroutine 启动
1
2
3
4
5
| func main() {
defer errorHandler()
var f func()
go f()
}
|
所有线程都休眠了
正常情况下,程序中不会所有线程都休眠,总是会有线程在运行处理我们的任务,例如:
1
2
3
4
5
6
7
8
9
10
| func main() {
defer errorHandler()
go func() {
for true {
fmt.Println("alive")
time.Sleep(time.Second*1)
}
}()
<-make(chan int)
}
|
能够被捕获的异常
数组 ( slice ) 下标越界
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| func foo(){
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
var bar = []int{1}
fmt.Println(bar[1])
}
func main(){
foo()
fmt.Println("exit")
}
|
空指针异常
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| func foo(){
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
var bar *int
fmt.Println(*bar)
}
func main(){
foo()
fmt.Println("exit")
}
|
往已经 close 的 chan 中发送数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| func foo(){
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
var bar = make(chan int, 1)
close(bar)
bar<-1
}
func main(){
foo()
fmt.Println("exit")
}
|
类型断言
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| func foo(){
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
var i interface{} = "abc"
_ = i.([]string)
}
func main(){
foo()
fmt.Println("exit")
}
|
参考