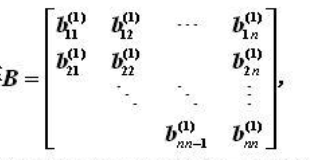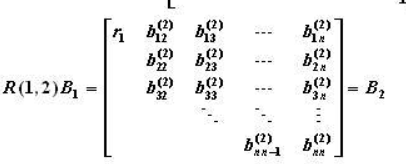本文最后更新于 2024年6月7日 下午
传统谱聚类算法实现步骤
构建邻接矩阵W
计算度矩阵 D
计算拉普拉斯矩阵矩阵 L
计算L的特征向量,k个最小的特征值对应的特征向量对应的特征向量组成矩阵Z
标准化Z
使用 K-mean 进行最后的聚类
并行谱聚类算法
引入并行的目的
为何要将传统的分布式算法改进为并行的分布式谱聚类算法呢?目得无外乎提升聚类速度与解决矩阵过大无法一次性载入内存。
所以我们追求的目标为:尽量使矩阵成为稀疏矩阵,这样既节省存储空间又利于加速聚类。
构造邻接矩阵
以往使用全连接法,每个节点之间都需要计算距离这显然是不符合我们的要求的。故此次我们采用“ε近邻法”构造进阶矩阵。
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 节点作为全局变量存在HBase中,最后构造出的邻接矩阵也存于HBase中input : <key ,null >key ,null >index = key key +1in [index ,anotherIndex]:in range( i,n):if sim < ε:else :output <key ,null >
可以看到,每次我们进行计算时,计算的是节点i与节点i、i+1、…、n节点之间的相似度。也就是说节点1需要计算n次,但节点n只需要计算1次,所以为了平衡每台机器上的计算量,将节点i与n-i+1的计算分配到同一台机器上。
计算度矩阵与拉普拉斯矩阵
伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ****Map函数****key ,value> (key 为行号,value为邻接矩阵第key 行对应的向量)key ,value>(key 为行号,value为该行元素求和)key for i in range (1 ,n):sum += value[i]sum )key ,sum >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ****Reduce函数****WData(index ) for i in range(1 ,n):if i==index:L(index ,i ,value -metrix [index ][i ]) else :L(index ,i ,metrix [index ][i ])
计算特征向量
难点
1. 利用Lanczos算法将拉普拉斯矩阵转换为对三角矩阵
Lanczos 算法
Lanczos算法认为若A为对称矩阵,则存在一个正交矩阵 $Q_n$,使得$T_n=Q_n^TAQ_n$成立,其中$T_n$为对三角矩阵
如何求出$T_n$呢?
$$
则
$$
$$
可令
$$
进行迭代
$$
$$
$$
$$
$$
$$
迭代停止条件为$b_n=0$
2. 利用QR算法不断迭代,逐步逼近矩阵的特征值
QR分解
算法的主要思想为:A=QR这一过程将矩阵分解为Q和R两部分,其中Q是标准正交矩阵,R是一个上三角矩阵。主要的分解算法有多种,这里对Given方法与Gram-Schmidt方法加以说明。
Given
对于一个给定的hessnberg矩阵
构造一个矩阵
其中
$$
$$
$$
相乘得
继续构造
最终对角线的左下角的元素全部清零
此时有公式成立
$$
$$
令
$$
开始新一轮迭代,重复数轮,最终矩阵B对角线上上的元素值即为原矩阵特征值。
下为迭代一次的Python代码,来自vonZooming的回答
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 def givens_reduce (matrix_a ):""" Givens reduce for QR factorization. :param matrix_a: :return: matrix_q, matrix,r Parameters: ----------- matrix_a: np.ndarray original matrix to be Givens Reduce factorized. """ for j in range (m): for i in range (j+1 , n): if matrix_r[i][j] == 0 :continue """ Find a and b (current entry) """ 2 ) + np.power(b, 2 ))""" Reduce R matrix """ 0 : m]for givens_matrix in givens_matrix_list:0 : m])return matrix_q, matrix_r
Gram-Schmidt
详细方法可以参照论文《QR Decomposition with Gram-Schmidt》
3. 利用特征值反推特征向量
并行化K-mean算法